第5章 两样本定量资料的比较
1. 概述与实验设计
假设检验的分类
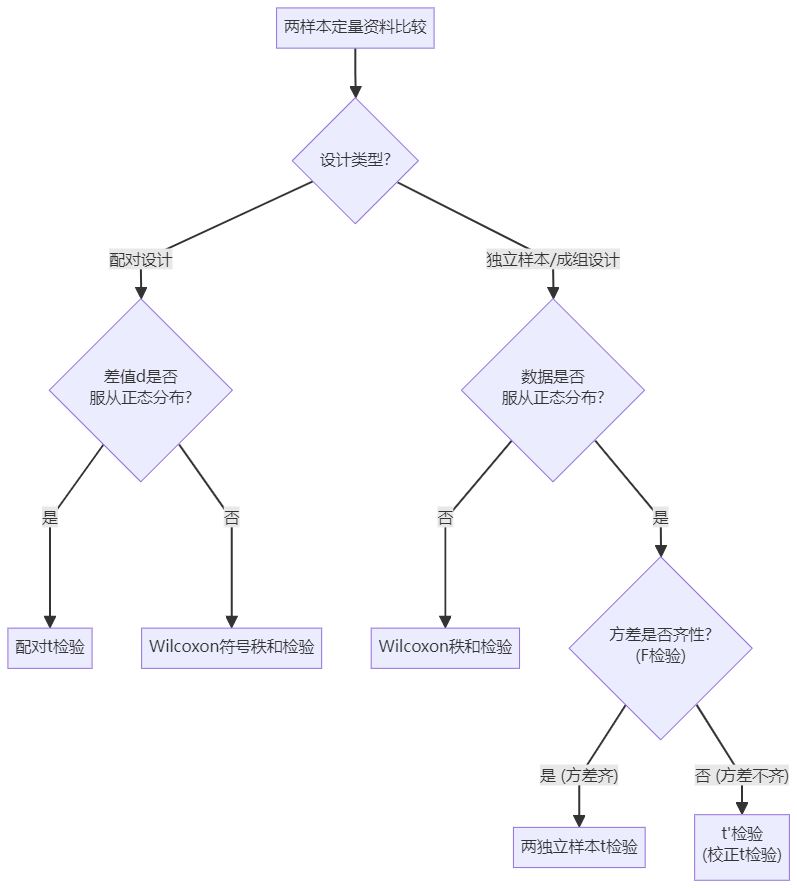
在医学统计中,根据设计类型的不同,两样本定量资料的比较主要分为两大类。
独立样本 (Independent Samples):完全随机设计,两组数据相互独立,互不影响。例如:实验组 vs 对照组,男性组 vs 女性组。
配对样本 (Paired Samples):配对设计,两组数据存在一一对应关系。例如:同一对象治疗前 vs 治疗后,同一对象左右侧对照,配对的两个受试者。

方法选择的逻辑
首先判断设计类型,区分是独立样本还是配对样本。
其次考察数据是否符合参数检验的条件,即正态性和方差齐性。
若符合条件,优先使用参数检验(如t检验),因为其检验效能(Power)较高。
若不符合条件,考虑使用非参数检验(如秩和检验)或进行变量变换。
例题:统计方法选择原则
在统计检验中是否选用非参数统计方法( )。
A. 要根据研究目的和数据特征作决定
B. 可在算出几个统计量和得出初步结论后进行选择
C. 要看哪个统计结论符合专业理论
D. 要看哪个P值更小
E. 既然非参数统计对资料没有严格的要求,在任何情况下均能直接使用
正确答案: A
解析: 统计方法的选择应基于设计类型、数据分布特征(如是否正态、方差是否齐)以及研究目的。若满足参数检验条件,应优先选用参数检验以获得更高的检验效能,而不是随意选择或仅看结果。
例题:设计类型的混淆与误区
以下说法不正确的是( )。
A. 完全随机设计两样本定量资料比较统计方法的选择最关键的是看是否满足正态性(样本量较大时不必进行正态性检验)和方差齐性。
B. 秩和检验编秩次时不同组间出现相同数据要给予“平均秩次”,而同一组的相同数据不必计算“平均秩次”。
C. 配对设计资料采用完全随机设计资料的统计检验方法会使检验效能升高,从而可能会使本来没有的差别被错误检测出来。
D. 假设检验中,无论拒绝不拒绝Ho,都可能会犯错误。
E. P是指 Ho成立时出现目前样本情形的概率最多是多大,是事先确定的检验水准。但P值的大小和\(\alpha\)没有必然关系。
正确答案: C
解析: C选项错误。配对设计资料如果错误地采用了完全随机设计(成组)的方法,没有利用配对设计消除个体差异的优势(误差变大),通常会降低检验效能,增加假阴性(II类错误)的风险,而不是使效能升高。
2.两组独立样本的比较
预检验:正态性与方差齐性
在进行两独立样本比较前,需进行预检验。
正态性检验:判断数据是否服从正态分布。常用方法包括:Shapiro-Wilk (W检验,适用于小样本)、Kolmogorov-Smirnov (K-S检验,适用于大样本)、矩法检验等。
方差齐性检验:判断两总体方差是否相等。常用 F检验。
例题:正态性检验方法
以下是正态性检验的是( )。
A. 矩法检验[h,p] = jbtest(x, alpha)
B. Shapiro-Wilk (W检验)
C. KS 检验(Kolmogorov-Smirnov test)
D. 符号秩和检验
E. LSD-t 检验
正确答案: A B C
解析: D是配对非参数检验,E是方差分析后的多重比较。A、B、C均为判断数据分布是否正态的常用方法。
方差齐性检验 (F检验)
目的:推断两个总体的方差是否相等,从而决定是选用 t 检验还是 t' 检验。
假设:
\(H_0: \sigma_1^2 = \sigma_2^2\) (两总体方差相等)
\(H_1: \sigma_1^2 \neq \sigma_2^2\) (两总体方差不等)
统计量:
\(F = \frac{S_{max}^2}{S_{min}^2}\) (即较大的样本方差除以较小的样本方差)。
判断:
若 \(F > F_{\alpha/2, \nu_1, \nu_2}\),则 \(P < \alpha\),拒绝 \(H_0\),认为方差不齐。
例题:F检验的应用
19. 以下检验用到F检验量的是( )。
A. 两个泊松分布的总计均数是否相等
B. 方差齐性检验
C. KS 检验
D. 符号秩和检验
E. 总体方差不相等且不符合正态分布的的两组独立样本检验其总体均数是否相等
正确答案: B
解析: F检验最典型的应用之一就是两样本方差齐性检验。
两独立样本t检验 (Two-sample t-test)
适用条件:
-
两样本来自正态分布总体。
-
两总体方差相等(方差齐性,Homogeneity of Variance)。
-
两样本相互独立。
基本原理:
推断两个总体的均数是否相等(\(H_0: \mu_1 = \mu_2\))。
统计量计算:
由于假设方差相等,需计算合并方差 (Pooled Variance) \(S_c^2\) 和合并标准差 \(S_c\)。
\(S_c = \sqrt{\frac{(n_1-1)S_1^2 + (n_2-1)S_2^2}{n_1 + n_2 - 2}}\)
t统计量公式:
\(t = \frac{(\bar{X}_1 - \bar{X}_2) - (\mu_1 - \mu_2)}{S_{\bar{X}_1 - \bar{X}_2}} = \frac{\bar{X}_1 - \bar{X}_2}{S_c \sqrt{\frac{1}{n_1} + \frac{1}{n_2}}}\)
自由度 \(\nu = n_1 + n_2 - 2\)。
例题:统计学意义的理解
两样本均数比较,其差别有统计学意义指的是( )。
A. 两总体均数的差别具有实际意义
B. 两样本均数的差别具有实际意义
C. 两样本和两总体均数的差别都具有实际意义
D. 有理由认为两总体均数有差别
E. 有理由认为两样本均数有差别
正确答案: D
解析: 统计推断是由样本推断总体,所以结论必须关于总体(排除E)。统计学意义(显著性)代表差别不是由随机误差造成的,但不代表有实际临床意义(排除A, B, C)。
例题:统计推断的逻辑
甲、乙两人分别从同一随机数字表抽取30个(各取两位数字)随机数字作为两个样本,求得 \(\bar{X}_1\)、\(\bar{X}_2\),则理论上( )。
A. \(\bar{X}_1 = \bar{X}_2\)
B. \(s_1^2 = s_2^2\)
C. 由甲、乙两样本均数之差求出的总体均数95%可信区间,很可能包括0
D. 作两样本均数比较的t检验,必然得出无统计学意义的结论
E. 作两样本方差比较的F检验,必然方差齐
正确答案: C
解析: 因为来自同一随机数字表,理论上 \(\mu_1 = \mu_2\),即总体均数差为0。因此95%置信区间有95%的概率包含真值0。D错在“必然”,因为即使 \(H_0\) 成立,仍有 \(\alpha=0.05\) 的概率犯I类错误(得出有差异的结论)。A、B错在样本统计量是随机变量,不一定相等。
例题:差异大小的判断
两样本均数比较时,能用来说明两组总体均数间差别大小的是( )。
A. t值
B. P值
C. F值
D. 两总体均数之差的95%置信区间
E. 上述答案均不正确
正确答案: D
解析: t值和P值反映的是统计学上的显著性(是不是随机误差),受样本量影响很大,不能直接代表差异的程度。置信区间直接估计了参数差值的范围,能反映效应量(差别)的大小。
两独立样本t'检验 (t' test / 校正t检验)
适用条件:
-
两样本来自正态分布总体。
-
两总体方差不相等(方差不齐,Heterogeneity of Variance)。
处理方法:
由于方差不等,不能合并计算 \(S_c\),标准误直接由各样本方差计算。
\(S_{\bar{X}_1 - \bar{X}_2} = \sqrt{\frac{S_1^2}{n_1} + \frac{S_2^2}{n_2}}\)
\(t' = \frac{\bar{X}_1 - \bar{X}_2}{\sqrt{\frac{S_1^2}{n_1} + \frac{S_2^2}{n_2}}}\)
校正方法:
Satterthwaite 法:校正自由度 \(\nu\)(通常算出为非整数)。
Cochran & Cox 法:校正临界值 \(t\)。
例题:方差不齐时的处理
10. 两独立样本定量资料的比较,如果数据服从正态分布但方差不齐时,应采用( )。
A. 秩和检验
B. 校正t检验
C. t检验
D. 配对t检验
E. 配对资料的符号秩和检验
正确答案: B
解析: 数据满足正态性但不满足方差齐性,属于Behrens-Fisher问题,应采用校正t检验(t'检验)。若也不满足正态性,才考虑秩和检验。
秩和检验 (Rank Sum Test)
适用条件:
总体分布呈非正态(偏态)。
总体分布类型未知。
等级资料。
方差明显不齐且无法通过变换修正。
方法名称:
Wilcoxon 两样本秩和检验 (Wilcoxon Rank Sum Test) 或 Mann-Whitney U 检验。
基本思想:
不利用原始数据的具体数值,而是利用数据的秩次(Rank)(即大小顺序)信息。
如果两总体分布相同,那么两组数据的秩次应随机穿插,两组的平均秩次应大致相等。
检验假设:
\(H_0\):两总体分布相同。
\(H_1\):两总体分布不同(对于位置参数,即两总体位置不同)。
编秩步骤:
-
将两组数据混合,统一从小到大编秩。
-
遇相同数值(Ties),若在同一组内,秩次顺延;若在不同组间,取平均秩次。
统计量 T:
通常取样本含量较小的那一组的秩和作为统计量 T。
若 \(n_1 > 10\) 或 \(n_2 - n_1 > 10\),可采用正态近似法(u 检验)。
例题:秩和检验的假设
两样本秩和检验的是( )。
A. 两样本秩和相等
B. 两总体分布相同
C. 两样本分布相同
D. 两总体秩和相等
E. 两总体均数相等
正确答案: B
解析: 非参数检验比较的是总体的分布特征(位置),其无效假设 \(H_0\) 通常表述为“两总体分布相同”。
例题:秩和检验的统计量
成组设计两样本比较的秩和检验,其检验统计量T是( )。
A. 为了查T界值表方便,一般以秩和较小者为T
B. 为了查T界值表方便,一般以秩和较大者为T
C. 为了查T界值表方便,一般以例数较小者秩和为T
D. 为了查T界值表方便,一般以例数较大者秩和为T
E. 当两样本例数不等时,任取一样本的秩和为T都可以查T界值表
正确答案: C
解析: 标准操作是取样本量较小的那一组的秩和作为统计量 T,因为统计表通常是基于较小样本量编制的。
例题:非参数检验的优缺点
对于两独立样本定量资料的比较,相对于参数检验而言,秩和检验的优点是( )。
A. 适用范围广
B. 检验效能高
C. 检验结果更准确
D. 充分利用数据的信息
E. 不宜出现假阴性的错误
正确答案: A
解析: 非参数检验不依赖总体分布类型,因此适用范围更广(等级资料、偏态资料皆可)。但其缺点是损失了部分信息(将数值转换为秩次),因此在满足参数检验条件时,其检验效能(Power)通常低于参数检验(更容易犯 II 类错误,即假阴性)。
3.配对设计定量资料的比较
配对设计 (Paired Design)
常见类型:
异体配对:将受试对象按某些混杂因素(如年龄、性别、体重)配成对子,同对的两个对象随机分配到两组。
自身配对:同一对象接受两种不同的处理(如治疗前 vs 治疗后,左眼 vs 右眼)。
核心思想:
关注的不是两组原始数据的均数,而是每对数据的差值 (\(d\))。
推断差值的总体均数 \(\mu_d\) 是否等于 0。
配对t检验 (Paired t-test)
适用条件:
差值 \(d\) 服从正态分布。
假设:
\(H_0: \mu_d = 0\) (即差值的总体均数为0,两方法/两时间点无差异)。
\(H_1: \mu_d \neq 0\)
统计量:
\(t = \frac{\bar{d} - 0}{S_d / \sqrt{n}} = \frac{\bar{d}}{S_{\bar{d}}}\)
其中 \(\bar{d}\) 为差值的均数,\(S_d\) 为差值的标准差,\(n\) 为对子数。
自由度 \(\nu = n - 1\)。
例题:配对检验的无效假设
15. 在配对检验中,其无效假设为( )。
A. 两样本均数不等
B. 差值的样本均数等于0
C. 差值的总体均数不等于0
D. 差值的总体均数等于0
E. 样本均数等于总体均数
正确答案: D
解析: 配对t检验的本质是单样本t检验(检验差值是否来自均数为0的总体),故 \(H_0\) 为 \(\mu_d = 0\)(差值的总体均数等于0)。
Wilcoxon 符号秩和检验 (Signed Rank Test)
适用条件:
配对设计的差值 \(d\) 不服从正态分布。
等级资料的配对比较。
零假设 (\(H_0\)):差值的总体中位数等于 0。
通俗理解:两组数据(如治疗前 vs 治疗后)没有本质差别,差值的分布是以 0 为中心的对称分布。
备择假设 (\(H_1\)):差值的总体中位数不等于 0。
通俗理解:两组数据有本质差别,差值的中心偏离了 0。
编秩步骤:
- 计算差值 \(d\)。
- 舍去 \(d=0\) 的对子,样本量 \(n\) 相应减少。
- 按差值的绝对值 \(|d|\) 从小到大编秩。
- 恢复差值的正负号,冠在秩次前面(正秩/负秩)。
统计量 T:
分别计算正秩和 (\(T_+\)) 和负秩和 (\(T_-\))。
通常取绝对值较小者作为统计量 \(T\)。
若 \(n > 25\),可采用正态近似法。
P值判定:
当样本量较大时,T值通常接近均值分布。
若计算得到的T值(较小的秩和)大于界值表中的临界值,说明正负秩和差异不大,P值大于显著性水平 \(\alpha\)(不显著)。
反之,若T值小于临界值,则P值小于 \(\alpha\)(显著)。
例题:符号秩和检验的P值
配对样本差值的Wilcoxon 符号秩和检验,确定P值的方法是( )。
A. T越大,P值越小
B. T越大,P值越大
C. T值在界值范围内,P值小于相应的 \(\alpha\)
D. T值>界值,P值大于相应的 \(\alpha\)
E. T值在界值范围上,P值大于相应的 \(\alpha\)
正确答案: D
解析: 符号秩和检验中,统计量 T 是正秩和与负秩和中较小的一个。如果 T 很大(接近总秩和的一半),说明正负分布均匀,差异不显著(P值大)。如果 T 很小(接近0),说明秩和主要集中在另一侧,差异显著(P值小)。因此,T值大于界值,意味着不够“极端”,P值大于 \(\alpha\)。
4.统计方法选择流程图